Dynamic schedule management framework
A-periodic soft-real-time jobs on GPU based architectures
Graphics Processing Units in Real-Time
Graphics Processing Units (GPUs) are computational powerhouses that were originally designed for accelerating graphics applications. However, in recent years, there has been a tremendous increase in support for general-purpose computing on GPUs (GPGPU). GPU based architectures provide unprecedented magnitudes of computation at a fraction of the power used by traditional CPU based architectures. As real-time systems integrate more and more functionality, GPU based architectures are very attractive for their deployment.
Based on where they are located and how they are used in a computing system, GPUs may be broadly classified into discrete GPUs (dGPUs), integrated GPUs (iGPUs), virtual GPUs (vGPU), and external GPUs (eGPUs). Personal computers generally use either discrete, also known as dedicated, GPUs (dGPUs) or integrated, also known as shared or unified memory architecture, GPUs (iGPUs).[1]
Real-Time Systems
However, in a real-time system, predictability and meeting temporal requirements are much more important than raw performance. While some realtime jobs may benefit from the performance that all cores of the GPU can provide, most jobs may require only a subset of cores to successfully meet their temporal requirements. In this work, we implement concurrent scheduling of a-periodic soft-real-time jobs on a GPU based platform, while optimizing the memory usage on the GPGPU. We target dGPUs as they are widely used.
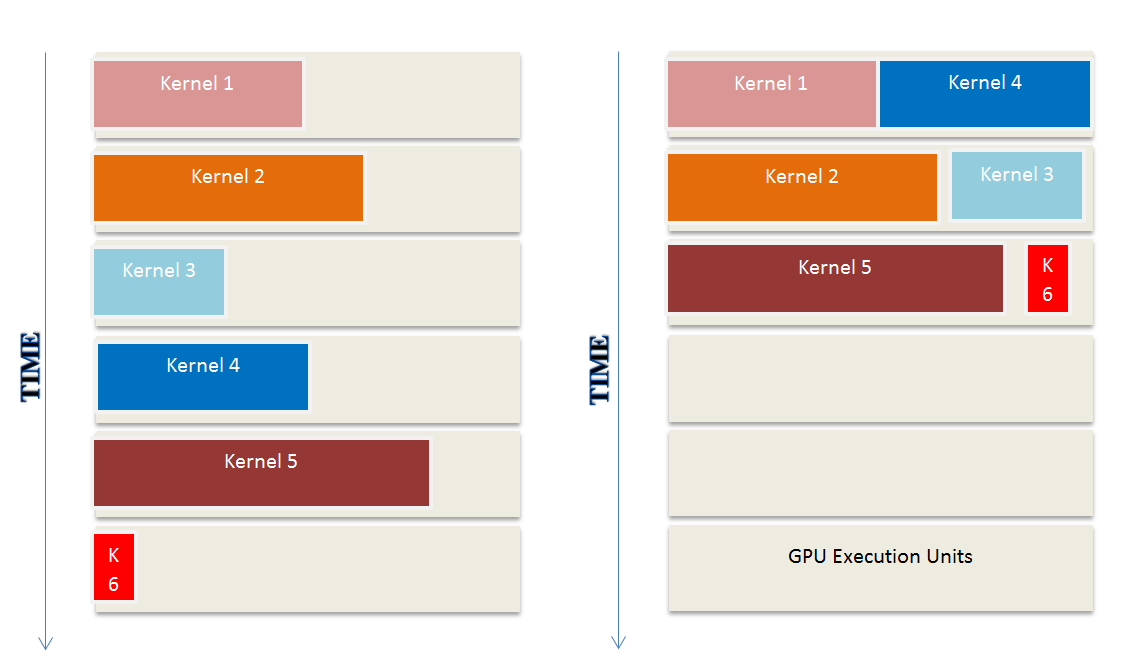
Real-Time Jobs
In real-time jobs, the concept of a deadline is fundamental, i,e., a real-time compute workload must finish its execution and generate the results to the consumed by another real-time compute workload. These jobs are generally termed as hard or soft real-time jobs based on their deadline fulfillment requirement. This concept of the deadline is achievable because these jobs have a very reliable execution time. To achieve reliable execution time one needs to get accurate estimates of the worst-case execution time (WCET) of the job for specific hardware architectures. Another major differentiating characteristic of the hard or soft real-time job is the priority of jobs, which means that a job with a higher priority has the right to execute before the job with a lower priority. These characteristics of the real-time jobs must be meet to deploy them safely on a GPU based architecture.
GPU Compatible Jobs
Jobs, also known as kernels, that are dispatched to the GPU for execution are usually jobs that involve performing the same set of operations on large volumes of data, i.e., jobs that map to a Single Instruction stream, Multiple Data stream (SIMD) model of parallelism. The GPU executes such jobs by launching many typically independent threads that perform a sequence of operations on a single data element. This feature allows GPUs to get unprecedented speed-ups when compared to other types of processors.
Not all jobs can be off-loaded on to the GPU, the jobs which are marked for GPU off-load needs to have very low or no divergence in the execution flow. This classification of job as GPU compatible or as GPU non-compatible needs to be done before we start the application. The jobs which are marked as GPU non-compatible will be scheduled exclusively on CPU. The GPU compatible jobs are sent to the GPU scheduler for evaluation, if the job is not off-loaded on to the GPU, the CPU scheduler will evaluate these jobs for scheduling.
GPU Challenges
Worst-Case Execution Time
To the best of our knowledge, no technique produces safe estimates of the worst-case execution time or WCET of jobs for GPU based architectures.
Job Preemption
Features that allow GPUs to get unprecedented speed-ups also makes it challenging to safely preempt a job. When a job is preempted, its context needs to be stored so that the job can resume execution from the point at which it was preempted. However, on GPUs, there is no known method to safely storing the context of each executing thread. This makes preemption of a GPU job infeasible — the job would essentially have to be restarted and intermediate results discarded. In early versions of GPU platforms, only one instruction stream or function represented by a kernel could execute on a GPU at any given time, regardless of GPU utilization.
CPU-GPU Data Transfers
The data transfers between the CPU and GPU happen over the PCI-e.
Motivation
Our motivation is to use the SRTG-Scheduler in a system that has both CPU and GPU. This system could handle the large compute workload generated by a plethora of sensors used in today’s real-time applications. By effectively off-loading as many jobs are possible on to the GPU, the scheduler can keep the CPU open for additional compute, while optimizing the GPU usage.
Solution
Worst-Case Execution Time
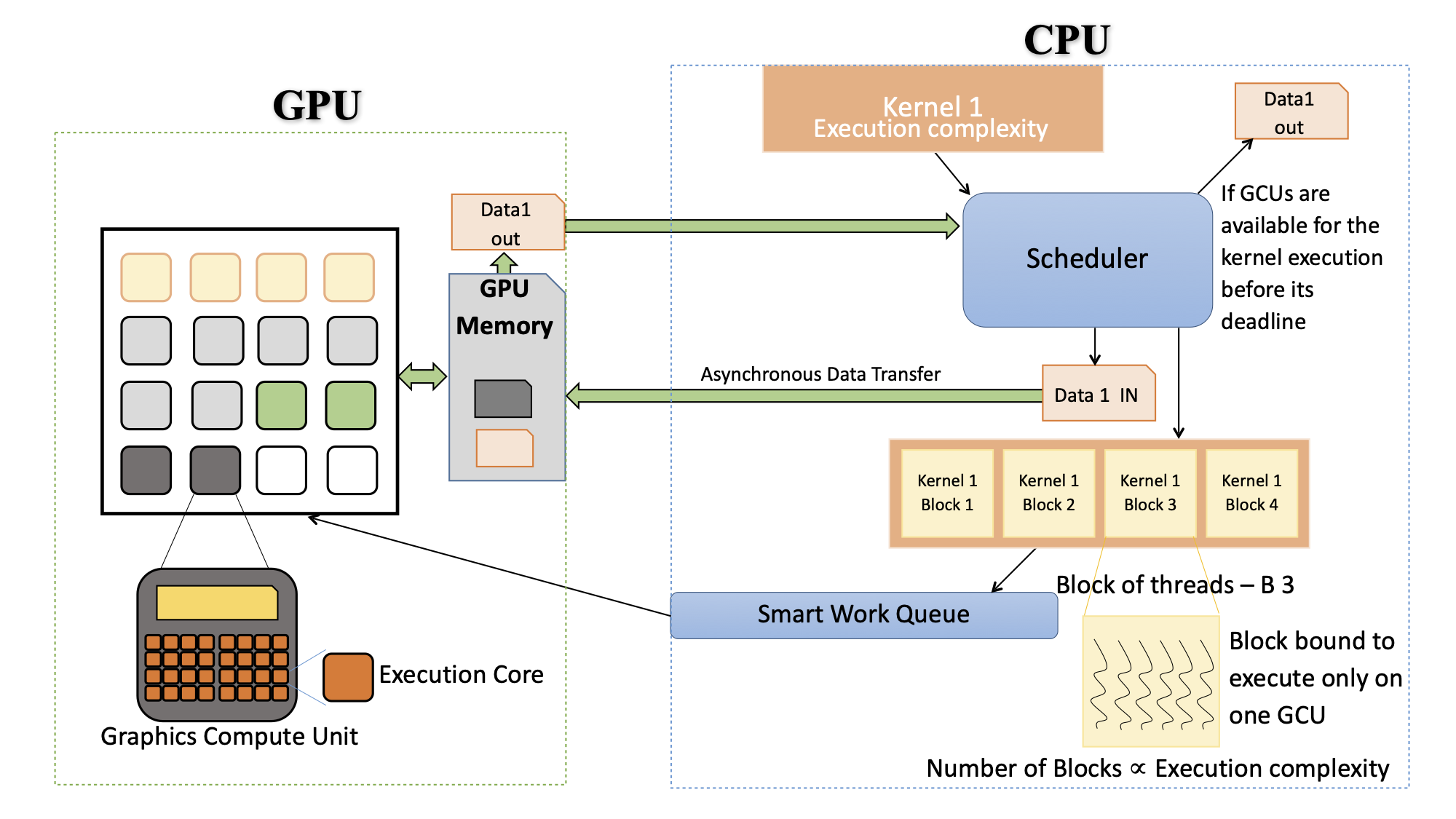
The generation of accurate WCET for aperiodic soft real-time jobs on GPU using the conventional methods is not feasible. Hence, we experimented with the statistical analysis method to generate WCET for jobs on the GPU. The jobs are forced to execute on a fixed number of GCUs and the execution time is measured over many runs for each job. The standard deviation was used to quantify the amount of dispersion of run time data from all the runs for each job, we observed low standard deviation when the jobs are running on the fixed number of GCUs, indicating that the observed run times tend to be close to the mean.
To get a more accurate statistical WCET we chose not to use the mean, but instead use a value which is two standard deviations from the mean value, because the jobs had a normal distribution with low standard deviation, choosing a number two standard deviations from the mean value would cover a very high percentage of the outliers giving us a more accurate bound on WCET. Given this premise, we can safely generate a statistical WCET for a job with any fixed number of GCUs allocated to it. Hence, we can make sure that a job meets its deadline by allocating the job its appropriate share of GCUs to complete its execution.
Job Preemption
Once the GPU scheduler accepts a job, the job will not be preempted or sent back to the CPU scheduler, thus eliminating the concern about non-preemptivity.
CPU-GPU Data Transfers
The statistical analysis method to generate WCET for jobs on the GPU as includes the PCI-e data transfer times, hence addressing the data transfers.
Our Approach
As we already established that there has been a tremendous increase in support for general-purpose computing on GPUs. More and more GPUs are being integrated into traditional CPU based architectural systems. As real-time systems integrate more and more functionality, GPU based architectures are very attractive for their deployment. But if the software support for the GPU off-load is limited or non-existent, a lot of computing is under-utilized. The GPU compute is also power-efficient, which makes it more attractive to offload as many jobs as possible on to the GPU and minimize the power utilization.
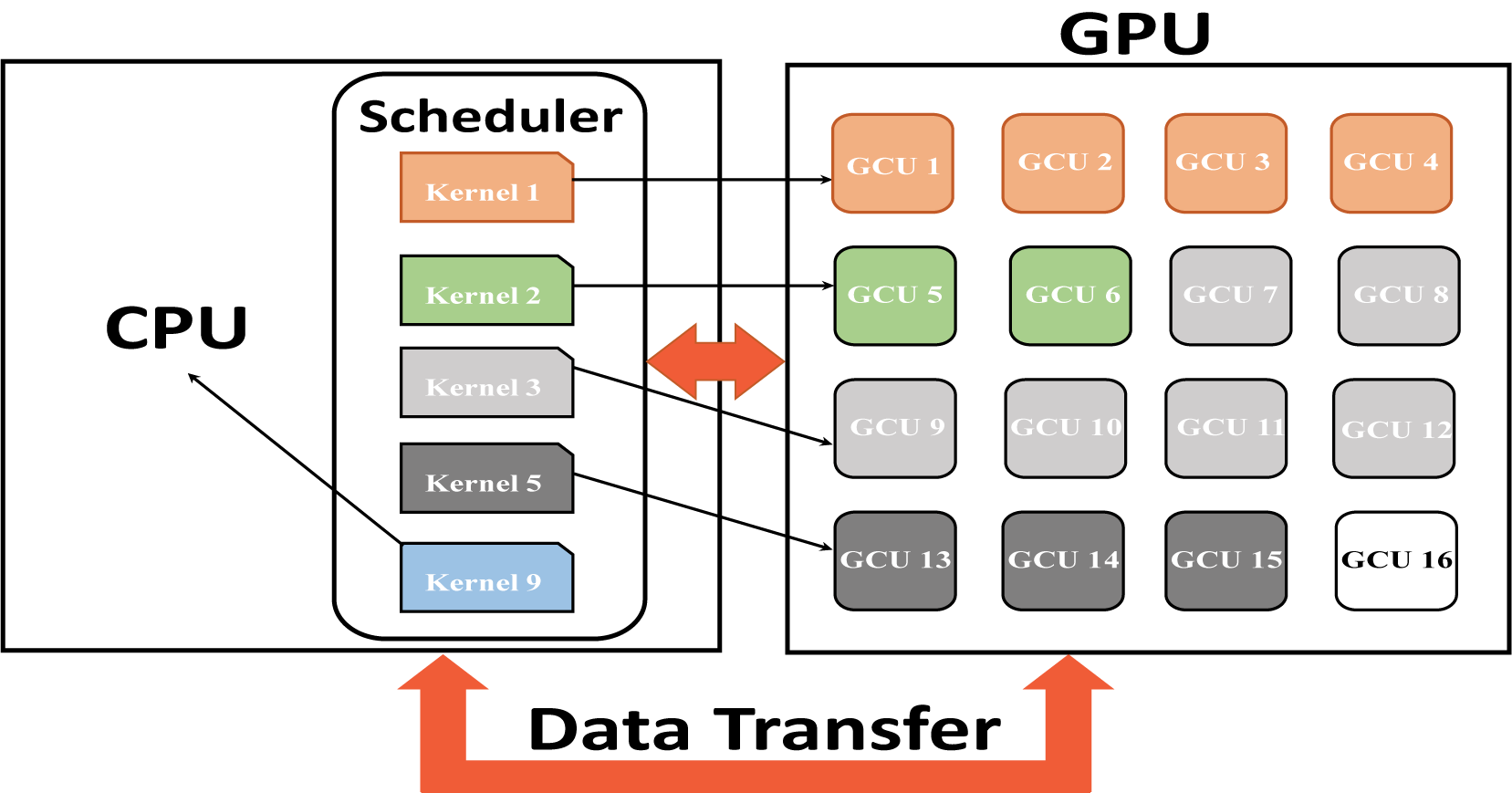
Our Scheduling framework resides on a CPU core and dispatches kernels to the GPU.
note:
- [1]The disparity in the nomenclature of these GPUs is due to the fact that naming conventions of GPUs are dependent on their manufacturers.